Video world models, which predict future frames based on actions, offer great potential for artificial intelligence. They enable agents to plan and reason within dynamic environments. Recent progress, especially with video diffusion models, has demonstrated impressive abilities to generate realistic future sequences. Despite these advances, a major challenge remains: maintaining long-term memory. Current models find it difficult to remember events and states from the distant past because processing long sequences with traditional attention layers requires extensive computational resources. This limitation restricts their capacity to handle complex tasks that need a sustained understanding of a scene over time.
A new paper titled “Long-Context State-Space Video World Models,” authored by researchers from Stanford University, Princeton University, and Adobe Research, presents an innovative solution to this problem. The authors propose a novel architecture that uses State-Space Models (SSMs) to extend temporal memory while preserving computational efficiency.
The fundamental issue arises from the quadratic computational complexity of attention mechanisms relative to sequence length. As the video context lengthens, the computational demands of attention layers increase dramatically. This makes long-term memory impractical for real-world applications. Consequently, after processing a certain number of frames, the model effectively “forgets” earlier events. This forgetting impairs its ability to perform tasks requiring long-range coherence or reasoning over extended periods.
The researchers’ key insight is to harness the natural strengths of State-Space Models for causal sequence modeling. Unlike earlier efforts that adapted SSMs for non-causal vision tasks, this work fully exploits their advantages in efficiently processing sequences.
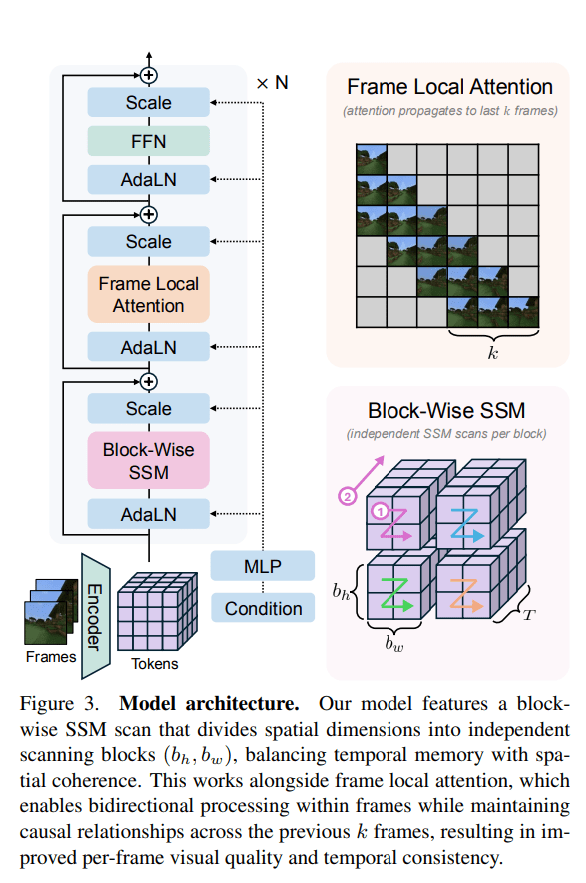
Their proposed Long-Context State-Space Video World Model (LSSVWM) incorporates several important design elements. Central to their approach is the block-wise SSM scanning scheme. Instead of applying a single SSM scan to the entire video sequence, the model processes the sequence in blocks. This approach trades off some spatial consistency within each block to achieve a significantly extended temporal memory. By dividing the long sequence into manageable blocks, the model maintains a compressed “state” that carries information across blocks. This effectively extends the memory horizon of the model.
To address the potential loss of spatial coherence caused by the block-wise SSM scanning, the model integrates dense local attention. This mechanism ensures that consecutive frames within and across blocks maintain strong relationships. It preserves the fine-grained details and consistency necessary for realistic video generation. By combining global processing through SSMs with local processing via attention, the model achieves both long-term memory and local fidelity.
The paper also introduces two key training strategies to enhance long-context performance. The first is diffusion forcing. This technique encourages the model to generate frames conditioned on a prefix of the input sequence. It forces the model to learn to maintain consistency over longer durations. Sometimes, the training involves not sampling a prefix and keeping all tokens noised. This scenario is equivalent to diffusion forcing, which the authors highlight as a special case of long-context training where the prefix length is zero. This approach pushes the model to generate coherent sequences even when starting from minimal initial context.
The second training strategy is frame local attention. To speed up training and sampling, the authors implement a “frame local attention” mechanism using FlexAttention. This method achieves significant speed improvements compared to a fully causal mask. Frames are grouped into chunks—for example, chunks of five frames with a frame window size of ten. Within each chunk, frames maintain bidirectional attention and also attend to frames in the previous chunk. This design provides an effective receptive field while optimizing computational load.
The researchers evaluated their LSSVWM on challenging datasets such as Memory Maze and Minecraft. These datasets are specifically designed to test long-term memory capabilities through spatial retrieval and reasoning tasks.
The experimental results show that their approach significantly outperforms baseline models in preserving long-range memory. Qualitative results, presented in supplementary figures, demonstrate that LSSVWM generates more coherent and accurate sequences over extended periods compared to models relying solely on causal attention or even Mamba2 without frame local attention. For example, in reasoning tasks on the maze dataset, their model maintains better consistency and accuracy over long horizons. Similarly, in retrieval tasks, LSSVWM shows an improved ability to recall and use information from distant past frames. Importantly, these improvements are achieved while maintaining practical inference speeds, making the models suitable for interactive applications.
The paper “Long-Context State-Space Video World Models” is available on arXiv.